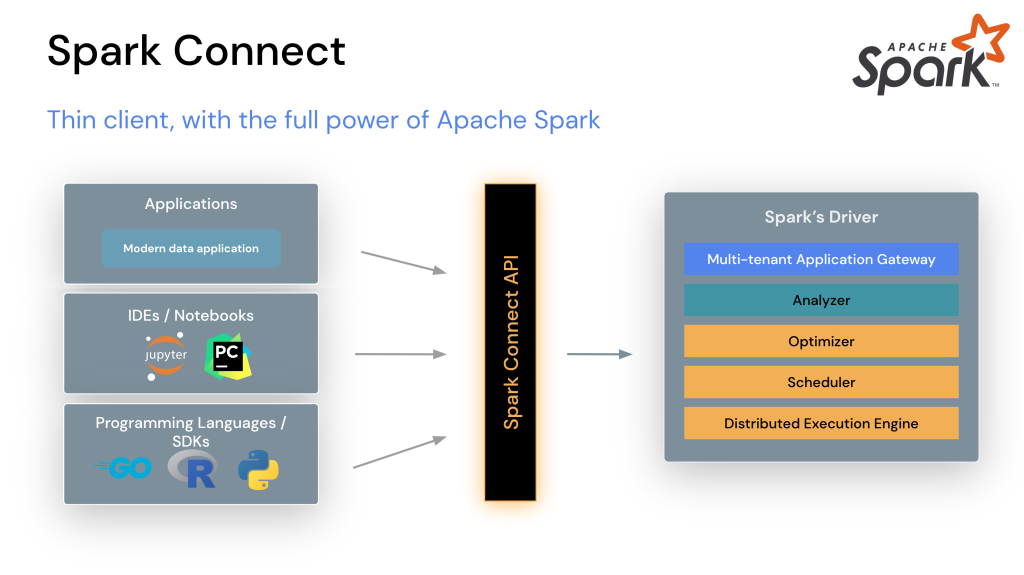
La herramienta está diseñada para trabajar con conjuntos de datos masivos en entornos de computación distribuida, permitiendo realizar análisis complejos de forma rápida y eficiente.
Spark permite ejecutar procesos de análisis de datos, machine learning, procesamiento en tiempo real y análisis de grandes volúmenes de información procedente de múltiples fuentes.
Entre sus capacidades se incluyen el procesamiento distribuido de datos, la ejecución de consultas analíticas, el análisis de datos en streaming y el desarrollo de modelos de aprendizaje automático mediante bibliotecas integradas.
Apache Spark se utiliza habitualmente en arquitecturas de datos, plataformas de análisis avanzado y sistemas de inteligencia de negocio que requieren procesar grandes cantidades de información.